


Why institutional investors and private equity firms should consider deploying private LLMs over public alternatives like ChatGPT and Gemini
Executive Summary
In December 2024, Italy’s data protection authority fined OpenAI €15 million for ChatGPT’s violations of the General Data Protection Regulation (GDPR). In April 2023, Samsung banned employees from using ChatGPT after engineers inadvertently leaked proprietary semiconductor source code through the platform. These incidents represent just the visible tip of a regulatory and operational iceberg that institutional investors must navigate with extreme caution.
This analysis explains why many institutional investors, particularly in private equity, may benefit from deploying their own private Large Language Models (LLMs), such as GPT OSS or Qwen, within a private Virtual Private Cloud (VPC). We argue that this approach can be preferable to relying on public LLM services like ChatGPT, Gemini, or Claude’s consumer or enterprise offerings.
While frontier models from OpenAI, Google, and Anthropic offer impressive capabilities, the regulatory landscape, silent risks, and strategic considerations facing financial institutions create a compelling case for private deployment in many scenarios.
What we mean by “Private LLM”
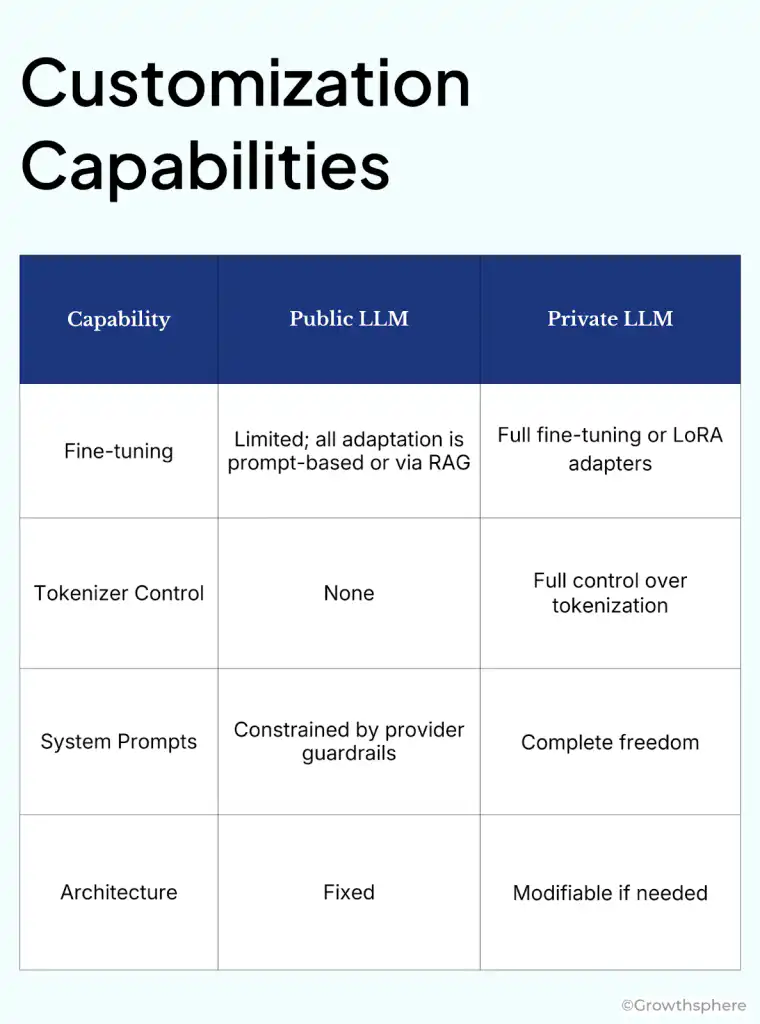
By private LLM, we mean physically downloading an open-weight model like Qwen 3 onto a private server and running inference directly from it. Critically, this does not include arrangements like ChatGPT on Azure VPC. While you can deploy an API endpoint into your Azure Virtual Network (VNet) for network-isolated access, the model itself remains fully managed by Microsoft/OpenAI.You do not get access to the weights.
With enterprise-tier public LLM offerings, you are a tenant, not an owner. This distinction carries profound implications for data control, customization, and regulatory compliance.
The “Samsung Moment”
In April 2023, Samsung employees accidentally leaked top-secret semiconductor code and meeting notes by pasting them into ChatGPT to optimize their work. It was a watershed moment forcing a realization across the corporate world that public LLMs are black holes for data. Once you feed confidential information into public LLMs, you no longer strictly control the information.
For a Private Equity firm, the threshold for confidentiality is very high. E.g. a PE firm analyst may accidentally paste confidential PDF of a target company’s unreleased Q4 financials into ChatGPT to summarize. This risk alone is enough to drive institutional investors toward private LLMs hosted on Virtual Private Clouds.
Some General Partners have already begun instructing Limited Partners not to submit any of their documents to LLMs, even premium services that promise not to retrain on user inputs.
The Regulatory Imperative: Laws that Constrain Public LLM usage
Financial services firms face an intricate web of regulations that may fundamentally conflict with public LLM providers’ data practices.
FINRA’s Framework
FINRA’s Regulatory Notice 24-09 (June 2024) confirms that existing securities laws apply to generative AI tools and firms cannot outsource regulatory responsibilities to third-party providers. Under Rule 3110, firms must supervise these systems despite their opacity. Key concerns include –
1. Recordkeeping obligations
2. Customer data protection
3. Regulation Best Interest compliance
4. Technology governance.
SEC’s Proposed AI Rules
The SEC’s July 2023 proposed rules would require broker-dealers and investment advisers to evaluate all AI-driven investor interactions for conflicts of interest. Then eliminate those conflicts, not merely disclose them.
The definition of “covered technology” explicitly includes LLMs like ChatGPT and Gemini. When using public models, firms have no visibility into training biases or whether outputs inadvertently favor certain products.
The SEC is also cracking down on recordkeeping. Investment Advisers Act Rule 204-2 requires strict retention of business communications, and third-party web interfaces rarely provide the immutable audit logs needed.
GDPR Exposure
Italy’s December 2024 fine found ChatGPT violated multiple GDPR provisions. For cross-border investors, the implications are severe because if European personal data enters a public model, you cannot honor erasure requests once it’s embedded in model weights.
Additionally, OpenAI’s consumer interface may use data for training without a data processing agreement, and cross-border data transfers remain under regulatory scrutiny.
Technical Risks
Beyond regulatory frameworks, technical vulnerabilities compound the exposure.
Model inversion attacks (example) can force LLMs to reveal training data. If your proprietary deal memos were part of a fine-tuning run on a shared enterprise cluster, they are theoretically discoverable.
Terms of service like “zero data retention” can change retroactively exposing your data. But with private infrastructure, you control the model weights and data logs.
Data Privacy and Sovereignty: The Core Advantage
Running inference outside a client’s Virtual Private Cloud raises inherent concerns under GDPR, FINRA, SEC rules, and other frameworks. These regulations emphasize data privacy, security, and auditability, guarantees that become increasingly difficult when data leaves a firm’s controlled environment.
| Dimension | Public LLM | Private LLM |
| Telemetry | Cannot inspect or guarantee what metadata is logged behind the scenes | Complete visibility into all logging and data flows |
| Data Flow | Data leaves your firewall; subject to provider jurisdiction | No risk of outbound data flow to any third party |
| Administrative Control | Provider is the admin | You are the only admin |
| Auditability | Limited logs; “black box” reasoning | Full trace of every prompt, token, and document accessed |
Anthropic has acknowledged this challenge and is actively researching solutions like Confidential Inference via Trusted VMs. It’s an approach aiming to ensure that sensitive data remains encrypted and is only decrypted within a verifiable, secure enclave during inference.
While promising, this is still emerging technology and may not yet meet the strictest compliance requirements for all financial use cases.
The Strategic Edge: Why Go Private?
Beyond regulatory risk and data privacy, there is significant alpha in owning your stack.
Model Consistency and Transparency
Public LLM providers frequently update their models and sometimes without notice. Silent API or LLM changes can break production workflows and we’ve observed significant differences in results between Claude model versions that required substantial prompt re-engineering to address.
With a private LLM, you gain:
- Reproducibility: Same model weights produce consistent outputs
- Version control: You decide when and whether to update
A private LLM can be fine-tuned on years of your Investment Committee memos. It will learn to speak your firm’s specific language, focusing on EBITDA add-backs, covenant structures, or sector-specific terminology in ways a generic model never can.
Although frontier public LLMs now support large context windows such as Gemini 3 Pro which offers up to 1M tokens, attention mechanisms still struggle with long contexts. The “lost in the middle” problem causes information in the center of long prompts to receive less attention than content at the beginning or end, degrading both recall and reasoning. Additionally, attention dilution occurs as context grows as the model’s focus spreads too thin across thousands of tokens, making it more susceptible to distraction by irrelevant information.
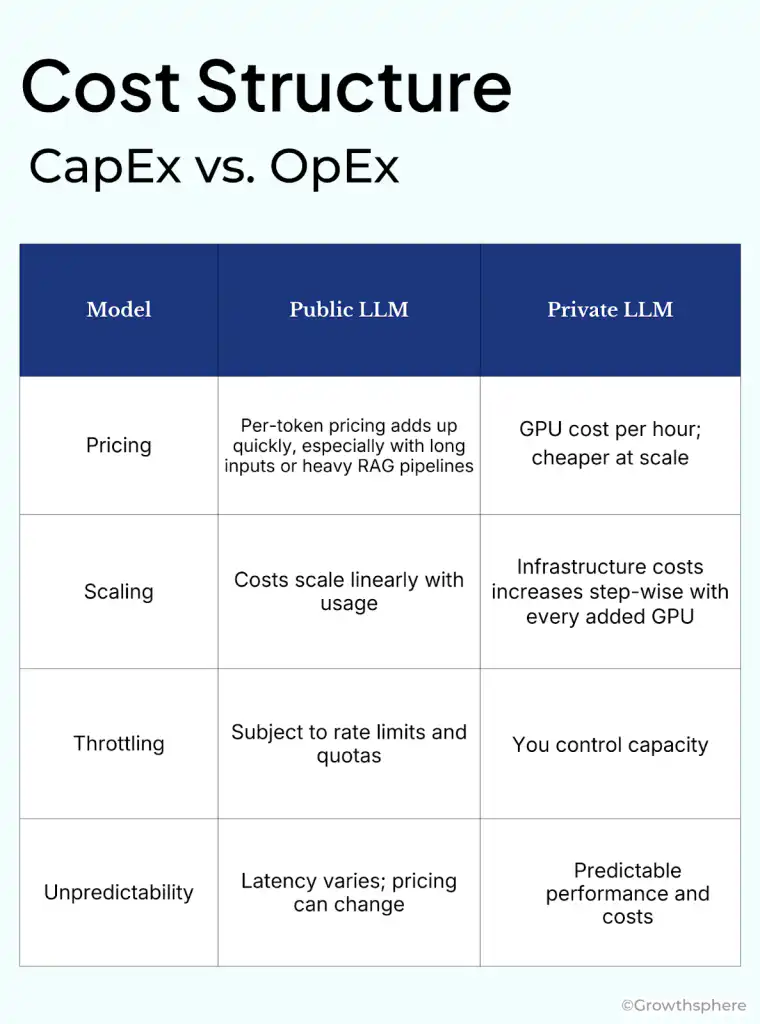
For moderate to heavy document processing workloads that is characteristic of PE due diligence, private deployment typically becomes cost-effective relatively quickly.
Bridging the Capability Gap
The common objection is: “But open-source models aren’t as smart as Gemini 3 or Claude Opus 4.5.”
This objection is overstated and may even be somewhat immaterial for institutional finance use cases.
The Narrow Gap
Open-source models are pretty competitive. E.g., as of mid-Dec 2025, Kimi K2 is 6th on the Artificial Analysis leaderboard with an intelligence index of 67 compared to Gemini 3’s 73 which is at the top of the leaderboard.
Deepseek V3.2 is at 66 and gpt-oss-120B is at 61. 8-bit quantization reduces GPU memory requirement with minimal hit to the model performance.
RAG
RAG (Retrieval-Augmented Generation) works well for fact extraction from Data Rooms. You do not need a model with a trillion parameters to summarize a legal contract.
For institutional investors, RAG offers compelling advantages:
- Current information: RAG can access the firm’s latest research, deal data, and market information
- Reduced hallucination: By grounding responses in retrieved documents, RAG significantly reduces the risk of fabricated information
- Auditability: RAG systems can cite sources, enabling verification of AI-generated insights
- No retraining required: Knowledge updates require only modifying the retrieval corpus
A smaller model (like Qwen 3 32B) that’s connected to a vector database of your internal deal history will often outperform GPT-4 for your specific workflows. Why? Because it has access to your data, not just the internet’s data.
Strategic Fine-Tuning
For domain-specific applications, which characterize most institutional finance use cases, the benchmark gap would be less material. A smaller model fine-tuned on financial documents can outperform a larger general-purpose model on finance-specific tasks.
E.g. we at Growthsphere fine-tuned Qwen 3 32B on our Private Equity ontology which outperformed Claude Sonnet 4.5 on knowledge graph extraction from PE docs. Also, Nvidia’s paper argues for employing several specialized fine-tuned SLM to solve atomic tasks in an agentic system.
For private equity, fine-tuning opportunities include:
- Investment memo generation calibrated to firm voice and format
- Due diligence question generation based on sector expertise
- Portfolio company benchmarking and analysis
- Regulatory compliance checking tailored to relevant jurisdictions
Hybrid Architectures
Many organizations are implementing hybrid approaches that combine the strengths of both private and public LLMs. Non-sensitive tasks such as general research, drafting blog posts for external website, or working with open-source code, can leverage public APIs, while sensitive activities involving proprietary data flow through private deployments. This architecture optimizes for both capability and security.
In the context of agentic systems hybrid approach means using a private LLM for sensitive tasks (e.g. draft an LP update on Fund IV performance), and using public LLMs for non-sensitive tasks (what’s the typical revenue multiple for mid-market healthcare IT?). Nvidia recently released a family of open models for building agentic AI applications.
When Private LLM Deployment Doesn’t Make Sense
Private deployment isn’t universally optimal. Standing up a private LLM requires engineering talent (MLOps) and GPU availability, so it’s best to consider public or managed alternatives under the following situations:
Scale is insufficient. Running capable LLMs requires significant GPU infrastructure. For instance, a 120B parameter model like gpt-oss-120B needs ~150GB VRAM with INT8 quantization. For organizations processing fewer than 8,000 queries daily, or unable to maintain 60–70% infrastructure utilization, cloud APIs would typically prove more economical. Firms under $500M AUM may find “private instances” of public tools (like Azure OpenAI Service with contractual protections) a valid middle ground.
Data sensitivity is low. General coding assistance, marketing content, and public market research involve no proprietary information. For these use cases, the operational complexity of private deployment isn’t warranted.
Speed matters more than control. Public LLM APIs offer immediate availability sointegration takes hours instead of weeks. For time-sensitive initiatives, this advantage may outweigh other considerations.
Long-context window. Public frontier models like Gemini 3 support large context windows out of the box while the leading open-weight models don’t. For workflows that absolutely require very large context windows, frontier models may remain necessary. Be careful though as LLM attention issues remain with large context (mentioned above).
Organizational readiness is lacking. Without existing ML operations capabilities, the ongoing burden of maintenance, security monitoring, and performance optimization may prove unsustainable.
The Strategic Imperative That Lies Ahead
For a private equity firm, information is the asset. Leaking it is fatal and losing control of it is negligent.
ChatGPT is powerful, but it is a public tool. You wouldn’t discuss your M&A strategy in a crowded Starbucks and you shouldn’t paste it into a public chatbot.
The choice between private and public LLM deployment is not merely technical. It is strategic, with direct implications for regulatory compliance, competitive positioning, and risk management. For institutional investors, particularly those in private equity, the calculus increasingly favors private deployment.
The regulatory environment is tightening. FINRA, the SEC, GDPR, and numerous other frameworks impose obligations that public LLM usage may inadvertently violate. The consequences of non-compliance like financial penalties, reputational damage, regulatory sanctions far exceed the convenience of public APIs.
The path forward requires thoughtful evaluation of use cases, regulatory obligations, and organizational capabilities. Many institutions will conclude that private deployment, whether fully on-premises or in a controlled cloud environment, represents the prudent choice for sensitive applications. Frontier models will always exist for use cases where superior capabilities justify the accompanying risks.
The institutions that navigate this transition most effectively will emerge with AI capabilities that are not merely powerful but sustainable. They will be compliant with evolving regulations, secure against data exposure, and optimized for their specific domains. In an industry where information advantage drives returns, that combination may prove to be the most compelling competitive advantage of all.





